Batch Prompting (cost reduction for LLMs/ChatGPT)

What are tokens?
Pealing back the onion, LLMs speak in tokens. Computers understand numbers and are really good at performing calculations with them, but too many numbers (and too many calculations) will have slow performance.
Enter tokens. Tokens are seemly random chunks of letters (sometimes english words, sometimes not) that are represented by a number. This compression from individual letters to chunks of letters reduces the number of calculations a computer needs to run in LLM, since one token may represent an entire word. OpenAI has a tokenizer playground for exploring how characters map to tokens.

Notice how ' back' or ' onion' are full tokens, but 'Pealing' comprises 2 tokens ('P' and 'ealing'). An overly simple reason for this is OpenAI defined these tokens based on the most common in their dataset. Common words are given their own token and less common words are comprised of smaller tokens.
Prompts with large samples create many tokens. More tokens, means higher costs. LLMs can actually batch respond to prompts if you build your prompt correctly so that the same samples can be applied to the same requests.

The Experience + Slogan examples consist of 62 tokens. The actual prompt itself is 17 tokens, only 25% of the total prompt token count. If you have multiple prompts that have the same examples, then you can use the same examples for multiple prompts in a single prompt. This may sound confusing, but let me break it down.
Save money with batch prompts
With batch prompting, the model will respond to multiple prompts within a single prompt, minimizing the number of tokens that need to be created. Samples are created and defined separately from the results.
Input prompt
Pretend you are a food reviewer that only writes positive slogans about a restaurant.
Experience[1]: The pizza was too soggy
Experience[2]: The owner gave my son a toy with his hamburger
Slogan[1]: Pizza is popular
Slogan[2]: Best family friendly hamburger joint
Experience[3]: The spaghetti sauce paired perfectly with the home made pasta
Experience[4]: The sushi rolls are creative, the artistry is wonderful and everything was absolutely delicious!
Experience[5]: I like how they have both an extensive burger and breakfast menu - hence the Bs! They kept my coffee going and even catered to a number of adjustments for my friends - now that's service!
(153 tokens)
LLM Output
Slogan[3]: Perfectly paired pasta, sauce and all!
Slogan[4]: Creative sushi, artistry on point, flavors divine!
Slogan[5]: Bs for breakfast, burgers, and beyond! Exceptional service and customization.
GPT perfectly associated the experience number with the slogan (without leaking any information across experiences). The batch prompt used 153 tokens, whereas single prompts used 66, 73, and 97 tokens respectively (totaling 236 tokens).
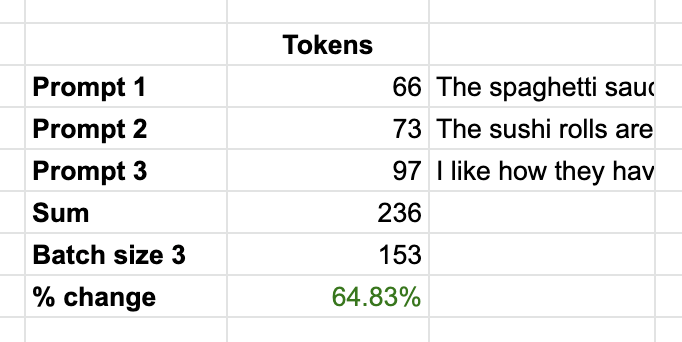
With batch prompting using this example, there is a 64% token reduction and cost savings, while achieving similar accuracy.
Final thoughts
This technique reduces LLM costs by 50%+ at minimal accuracy degrdation. This technique is perfect for processing millinos of prompts for summarization or entity extraction, but at a low cost.
A word of warning: this technique isn’t free. There is ~3% decline in accuracy comparing a batch size of 4 to a single prompt, with an even sharper drop of accuracy from batch sizes of 4 to batch sizes of 6.
Additional reading
- Batch Prompting: Efficient Inference with Large Language Model APIs (arxiv.org)
- Prompt Engineering Reading Library (github.com)
- Prompt Engineering Walk-through colab notebook (github.com)